
When choosing a communication layer for a software solution, your company will likely face the GraphQL vs REST dilemma. Let’s quickly have a look at both of them before jumping into some practical examples, which will hopefully help you to reach a final decision.
What Is REST?
The title alone may startle non-technical readers, but we’ll try to keep this as straightforward as possible. In today’s article, Software Planet Group are taking a look at application programming interfaces (or APIs), which have often been described as an agreement between developers on how devices and applications should be exchanging data with their parent servers.
REST, or representational state transfer, is a software communication architecture pattern which revolves around the idea of the resource. Every resource — which may be anything from users, authors or articles — is identified by a separate URL, and can then be fetched by sending out an unambiguous GET request. Unlike other APIs, REST provides no special tooling or libraries. It is merely a set of instructions on how to access all the data you need.
Nonetheless, this by no means means that REST is short in the merit department. Especially over HTTP2, for instance, it provides exceptionally high performance, is able to scale indefinitely and works with server-driven application states (the server lets you know exactly what you can call and when).
Yet though REST may have proven itself for decades, more recently, a strong contender has emerged to give the protocol a run for its money.
What Is GraphQL?
Developed by Facebook back in 2012, GraphQL, by contrast, is an open source query language. Its most obvious distinguishing feature is the so-called GraphQL schema, which provides a central location where all the data is effectively described. Though initially, the way in which you fetch resources is in fact fairly similar to REST, the obvious difference here is where developers can go from there.
For instance, while GraphQL delivers additional data by following relationships defined in the schema, in REST this is impossible unless the programmer sends out multiple requests. Not only does this give clients much more control over the information being sent, but data fetching can also be entirely UI-driven.
Take AirBnb’s search page as an example. Here, you will frequently see results for houses, flats, adventures, and other related experiences. In order to do this with a single request, AirBnb make use of a GraphQL query that is instructed to select only UI-specific information. This creates an ingenious separation of concerns, as the client handles requirements while the server is left to deal with the data structure. As a result, GraphQL is able to make data transfers significantly more efficient.
What Are the Drawbacks of REST?
But of course, not everything is sunshine and rainbows. Especially when different vendors are responsible for your app’s frontend and backend, the REST protocol may indeed be prone to a number of unexpected surprises. One commonly cited issue is that because REST is so reliant on endpoints, frontend developers are often forced to wait for their backend counterparts to do their jobs. This causes unnecessary delays and an unwarranted degree of frustration. By contrast, with GraphQL, you can always access the data you need without specifying it all beforehand.
Furthermore, REST’s aforementioned lack of tooling calls for discipline from all parties involved.
Are There Any Disadvantages to GraphQL?
As for GraphQL, though it is undeniably more flexible than REST, the added flexibility will also come at a perceptible cost. If, for instance, an ill-intentioned individual were to gain access to your client-side code, they would be able to structure malevolent requests that could potentially overload your system. Consider a massive report requesting data from the previous 10 years. Put mildly, your servers would seriously struggle to cope! Of course, with appropriate security, this danger may also be substantially curbed.
GraphQL may also not be ideal when dealing with microservices, as it does not currently possess the ability to return data from multiple services. This, by contrast, can be accomplished rather easily with REST.
Moreover, GraphQL sometimes leads to bikeshedding, as too much time is spent on largely tangential matters like network errors, content negotiation and caching.
Decision Time: GraphQL vs REST?
If you’ve made it this far, congratulations! You now have a solid understanding of two incredible available APIs. So which to pick for your next software project? Well, as always, there is never really a silver bullet, as this will inevitably depend on a variety of different factors.
In general, however, those who are committed to following REST API’s best practices will probably be convinced that GraphQL falls a little flat. On the other hand, if you are looking for the very latest in API technology, with a client-centric protocol that is trusted by major brands, then Facebook’s GraphQL query language will all but certainly serve you well.
Whatever your final decision, of course, SPG have got you more than covered!
GraphQL vs REST: Practical Examples and Nuances
While the above may make it all seem cut-and-dried, when it comes to choosing between GraphQL and REST, there is also room for nuance and overlap, so let’s dive in deep with some technical examples.
Because REST (or RESTful) is primarily about dealing with outstanding resources, let’s imagine that our business domain would include objects such as companies and members. In this way, if we wanted to send in a request to fetch a particular company or a user, we would be given all its respective attributes (including name, ID, etc). Outlined below are two different use cases from the client’s perspective:
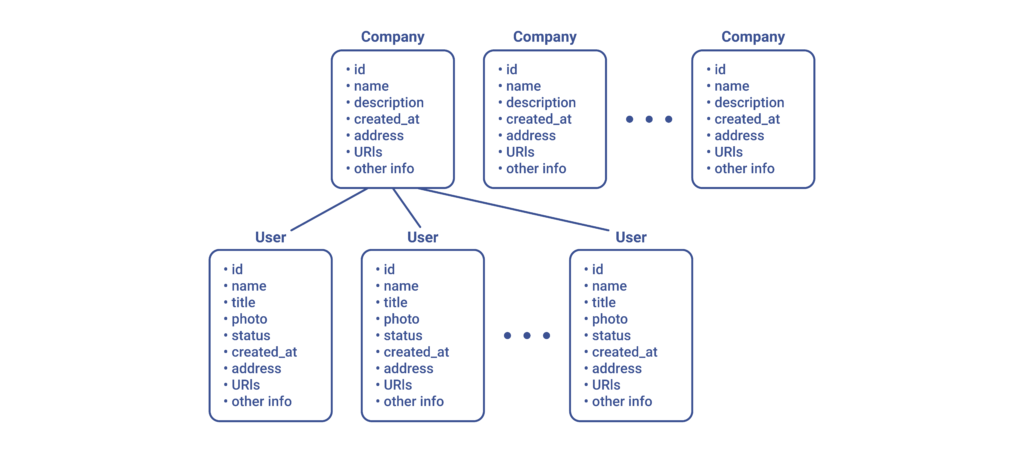
Use Case 1: Select a Company via Input with Autocomplete
Our application should allow the end user to select a company with the help of a special input box featuring autocompletion. For example, if the end user entered a substring, the application would then ask the server to locate the companies with that substring in their name. This essentially would mean that upon each request, we’d be able to fetch from the server a list of companies with all their included attributes. Bear in mind that this would happen whether or not we only required a more specific set of company data.
So let’s highlight the fetched information with the colour red:
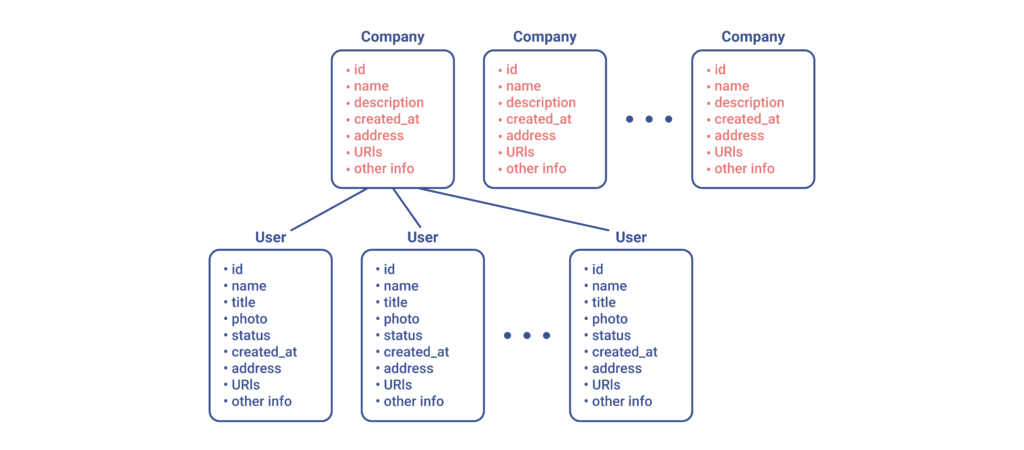
Use Case 2: REST API and the N+1 Problem
Now, let’s imagine the same autocompletion or company search page from the client’s perspective, and go ahead and also determine that for every company that is found, their respective CEO’s name should be immediately apparent to end users. In order to accomplish this with the simplest possible REST implementation, the client side will be forced into a 1+N situation. Or, stated in another way, for every company that is found, we will have to send the server a second request — this time asking for all of its members — and thereby locate the member with the title CEO.
A Quick Note: N+1 or 1+N
Before venturing further into our example, let's make sure we get our terms straight. In the ORM world, there is a well-known problem called "lazy loading" or the N+1 problem. This happens when a query is made for a parent record in a database, before an additional query is required to gain access to every child record. As shown in our example below, while working with API, one may face a somewhat similar situation: in order to gain access to all required information from the server (e.g. the list of companies and related data), you have to first send in a request (to obtain the list of companies) before sending N more requests (one per each company from the list) to be given the details you need. This situation is often referred to as the "N+1 problem", but from a technical point of view, it would actually be more accurate to call it "1+N" (as we make 1 + N requests), so we'll be doing that for the rest of this article.
Let’s highlight what would be downloaded now:
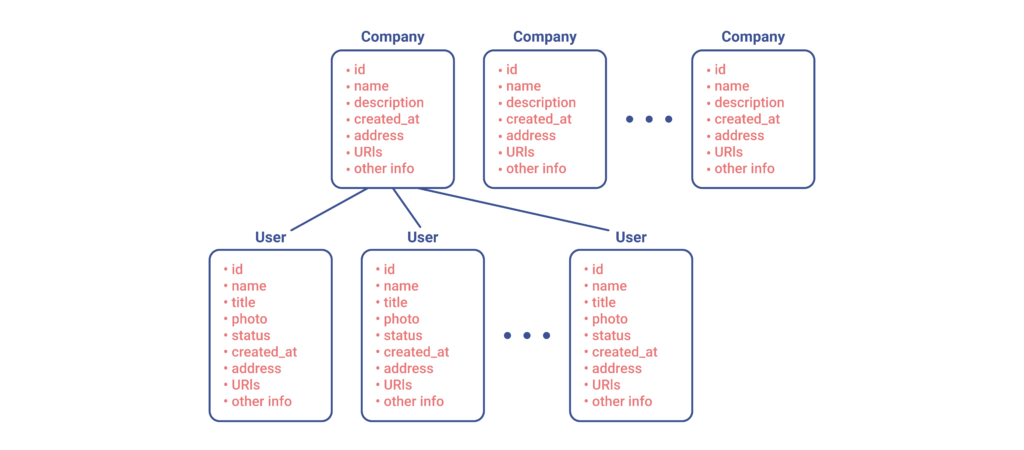
Of course, sooner or later, the “ideal REST implementation” becomes impossible to maintain, and we will have to apply our own optimisations. For instance, if we add a new term to our business domain, like company CEO, we can fetch it as an outstanding resource. In this way, we can still have 1+N queries, but we will now be given a single User per company, which would include the title CEO.
Let’s highlight what we have downloaded as a result:
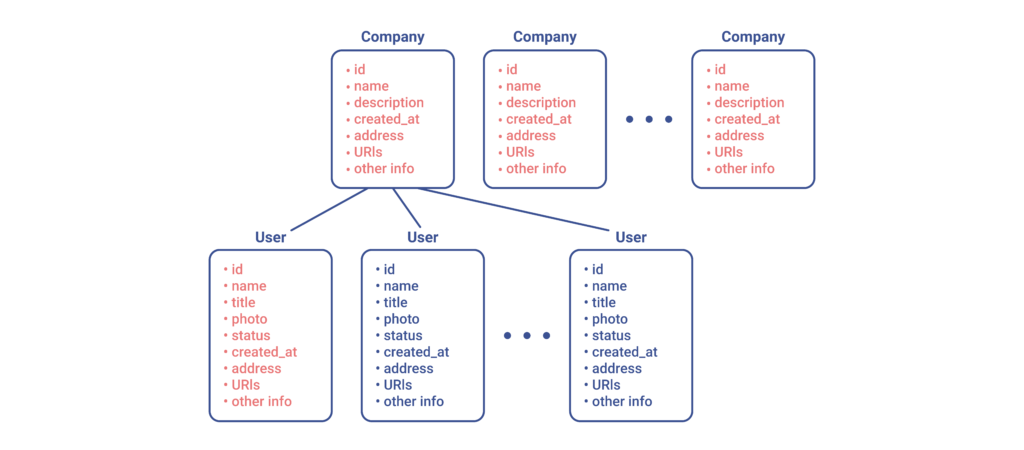
Next, we can optimise even further by reverting to a single query instead of dealing with a 1+N setup. In this way, when attempting to fetch a new company, we can attach an additional field to it — e.g. CEO — which corresponds to the respective User object. Consequently, we would still download all the same parts that were highlighted in the previous diagram, but this would now be handled as a single query.
API Call Optimisation: the Jedi Way
But let’s get back to Use Case 1 for a minute. After all, it is important to realise that although it only calls for a single company name, we would also be doing a lot more computation and DB queries than is normally required (as we’d be looking for a company CEO) and in the end download more data than we actually need.
As a result, our optimisation of Use Case 2 now has an impact on other use cases as well. Of course, this is never a serious issue when the impact is limited to having more fetched data, time or resources, but at times, it may also break other things or create conflict from a technical perspective. This happens because we opted to do away with a conservative implementation of REST in order to benefit from outstanding resources (while still linking them to one another in accordance with the business’ needs).
Now let’s consider yet another approach. For instance, what if we could tell the server what exactly it is we need to fetch? In order to do this, let’s get back to our Use Case 1, assume that we are able to ask the server to search for companies using a name substring and finally, that it can also provide us with a set of names — and names only — as a valid response.
In this case, we would only download the following data:
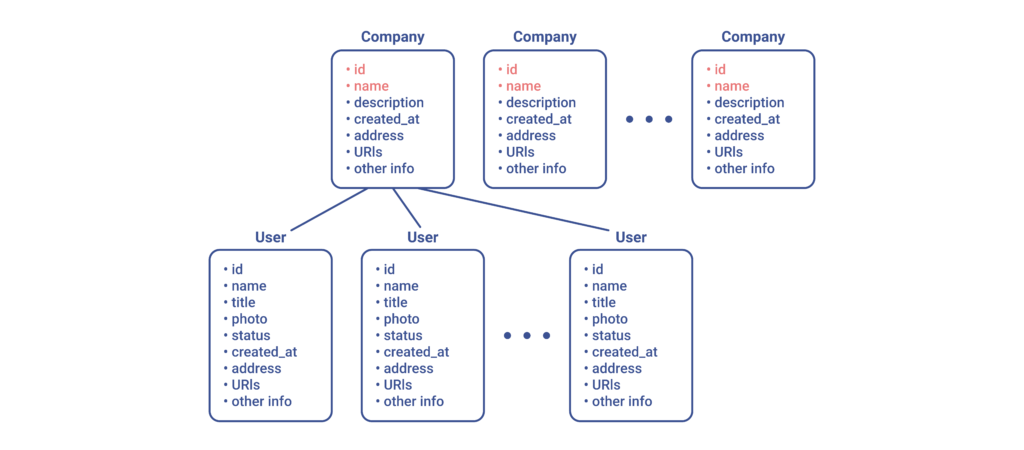
Of course, from a technical perspective, we would still require an ID to initiate any server request, but this would now demand less input to be given data from the cache or database, and it would also lead to faster transfers. Moreover, the server will also not be wasting any time trying to find a CEO or the like.
Getting back to Use Case 2, however, what we would now like to do is ask the server to repeat the search by name, but also to locate company CEOs and add their names to the query response (at the moment, we do not need all of these users’ details). Thus, we would now fetch the following:
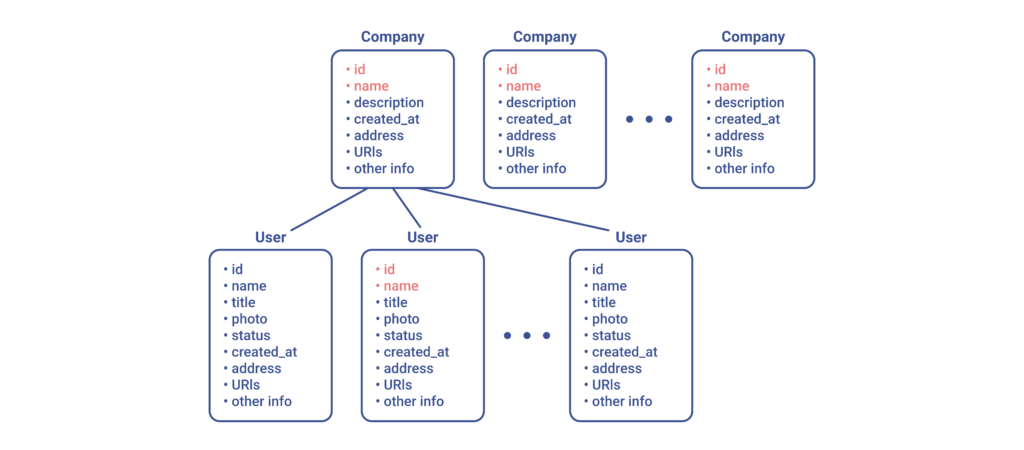
But what if the user were to click on one of the downloaded companies? Well, in that case, we would probably want to ask the server to fetch all attributes pertaining to that resource in particular:
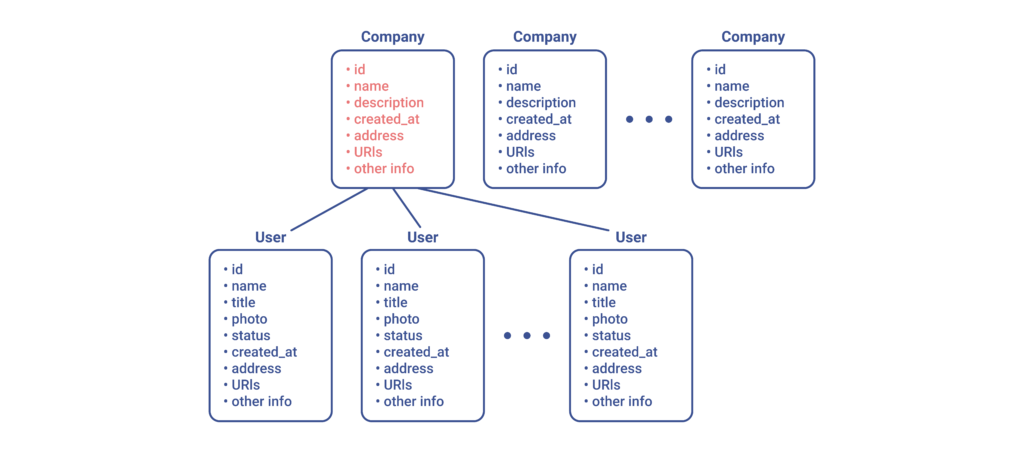
Similarly, we would also have to ask the server to load a CEO’s photo and details whenever the user would like to inspect their profile.
Can the Same Be Done With REST?
Though it’s possible to achieve these same levels of flexibility with the REST(ful) approach, this is certainly not a standard procedure, as there are a myriad of other ways of accomplishing similar things with additional HTTP query parameters, headers and body. Some best practices are even included in different protocols or agreements — OData being one of them. In addition, over the years, many web frameworks have added built-in support for these approaches.
At the same time, however, not every application will find these techniques particularly elegant or easy to work with for their own project’s intended purposes. This is more often than not the case if they were conceived as an HTTP hack when the latter was not designed for this kind of data fetching optimisation.
On that note, let’s quickly remind ourselves of what HTTP stands for: Hypertext Transfer Protocol. Of course, Hypertext itself is the idea of a network of documents in which each document may be linked to any number of additional documents. This is the fundamental concept upon which RESTful is based — we just substitute documents with our business objects instead. When this concept plays nicely within a global network, as the above technical example makes clear, it could quickly become a bit cumbersome (in terms of efficiency and overall performance) for smaller businesses or applications.
On the other hand, because many network protocols may be extended or used as a base for a brand new protocol, we can use HTTP as a mere transfer mechanism and build a new protocol of data transfer and manipulation which would be a better fit for the aforementioned cases. This would cover our technical needs of both fast and optimal data fetching — as lest we forget, in this day and age, every second should count for the customer.
Facebook’s View on the GraphQL vs REST Issue
Interestingly enough, Facebook was once faced with a very similar issue, as their enormous amount of linked data called for efficient querying of information. This is why the company stands behind technologies such as GraphQL, which may be thought of as a proper standard as opposed to a set of best practices. Over the years, GraphQL has grown into an open source technology which provides us with an interesting alternative to the questions of data fetch, manipulation, and data change notification.
Though it unfortunately also comes with the additional cost of technical complexity, it benefits equally from a plethora of libraries, practical tools and essential best practices: like GraphiQL, Relay, Apollo and Hasura, to name just a few. Of course, using simple REST endpoints may be entirely sufficient for your company, but if your project is becoming more complex with every iteration, then you would probably be better off migrating to GraphQL. The same goes for those who from the very start of the project are convinced that they are likely headed towards much higher levels of complexity.
At the same time, you may well start with tried-and-tested approaches like REST and later go further with tools like Hasura to wrap your REST/SQL data sources into a fully-functioning GraphQL API. In any case, as explained at length above, when it comes to GraphQL vs REST, each approach will have its own pros & cons.
Looking for API design and development specialists?
At SPG, we're capable of designing robust APIs for complex solutions and would be delighted to help you deal with the GraphQL vs REST dilemma!
Call API Specialists

