
What Is a Vector?
A vector is a numerical representation of an object. For instance, a two-dimensional vector could look like (2, -3). You can imagine it as a line segment from the origin (0, 0) — which is usually omitted — to the point (2, -3). More generally, a vector is simply an array of numbers, where each number corresponds to a coordinate in a given dimension.
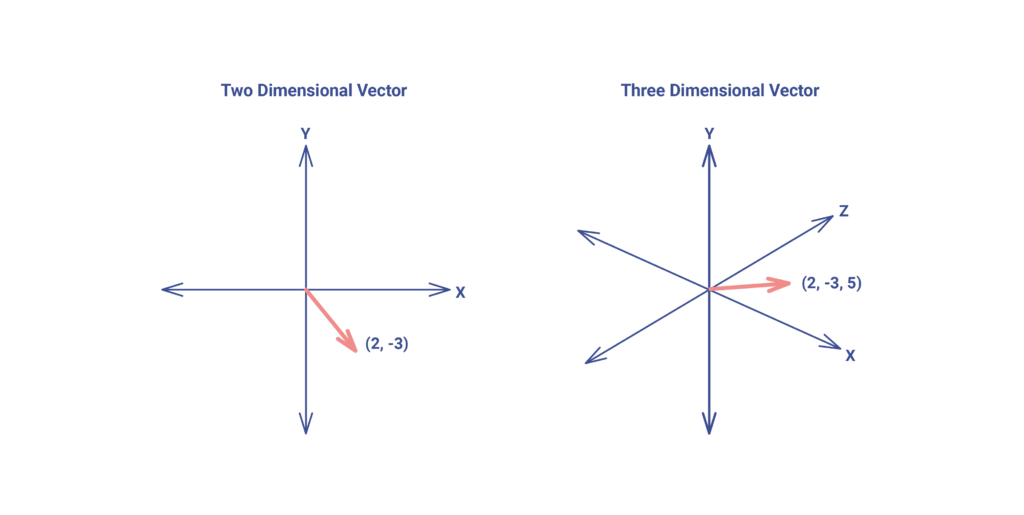
It’s important to understand that the number of dimensions is not limited to two or three — we can have hundreds, thousands, or even more. And here’s where it gets interesting: almost any object — a word, an image, or a sound — can be represented as such a numerical array. We pass the object through a model — often a machine learning model — and what we get is a vector: a mathematical abstraction, if you will.
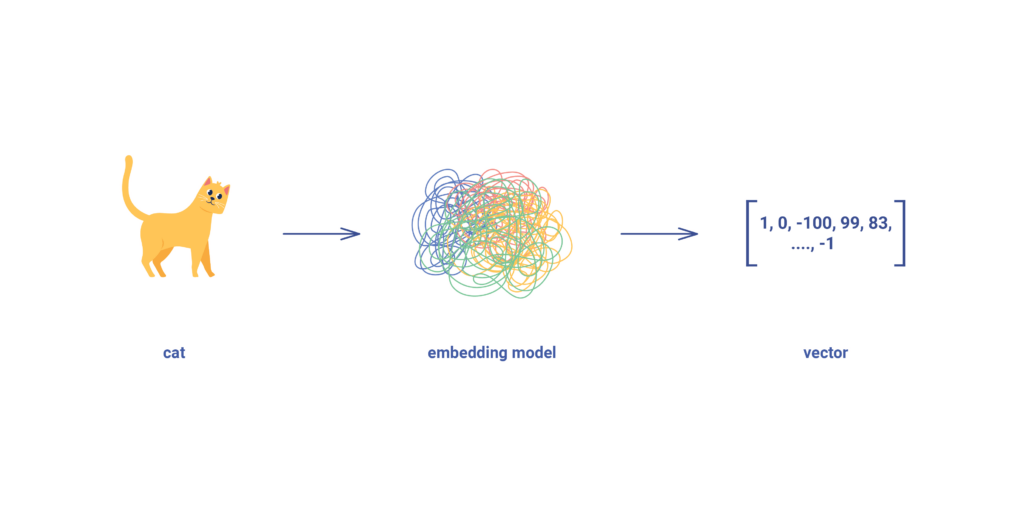
This process is called vectorisation (or embedding) — transforming real-world data into numerical form suitable for computation and comparison. These embeddings are later used for vector similarity search and stored in a vector database.
Why Does This Matter?
Imagine you are building a next-generation marketplace designed to disrupt the industry. You start with a classical relational database to store product information: colour, price, model, and so on. Everything works fine — until your business team comes with a new request:
“Let’s implement recommendations for similar products.”
Fair enough. At first, you might try recommending products from the same category, or those that share attributes like colour or size. But there’s a catch: the perfect recommended item may not match any of these fields directly, yet still feel similar to the user.
And that’s the problem: traditional databases have no concept of “similarity” beyond exact or rule-based matching. As a result, they’re ill-suited for tasks like semantic search, embedding search, or AI-powered recommendation systems.
To build systems capable of understanding meaning, we turn to machine learning — where we work with vectors, compare them, and perform mathematical operations to find patterns and similarities. This is where vector databases come in — databases specifically designed for storing and querying high-dimensional vectors using vector search technology.
What Is a Vector Database?
A vector database is a specialised system for managing high-dimensional embeddings, enabling fast vector similarity search at scale. It is often described as the backbone for modern AI applications like recommendation engines, semantic search, and computer vision. If you’re wondering what is a vector database, it’s essentially a database that can perform nearest neighbour search on vector data.
Standard databases are not designed to handle high-dimensional vectors. They are optimised for rows, columns, and indexes — not for arrays of 512, 1024, or even 4096 numbers. That’s why we need something purpose-built like a cloud-native vector database.
Enter Vector Databases
Vector databases are designed specifically to store, index, and query high-dimensional vectors efficiently. Here’s how the general workflow looks:
- An object — say, an image — is received as input.
- It is processed by a model that generates a vector embedding.
- That vector is then stored in a vector database.
- When we want to find similar objects, we run the same embedding process on a new item and compare its vector with the stored ones using nearest neighbour search.
This comparison isn’t based on equality, but on proximity in high-dimensional space — a concept known as nearest neighbour search. The database vector structure makes this fast and scalable.
Traditional indexing methods don’t scale well in such spaces, so vector databases use specialised algorithms and data structures. If you’re wondering what is vector database or how it compares to traditional systems — the answer lies in how they handle semantic similarity across large datasets using vector embeddings.
How Does Vector Search Work?
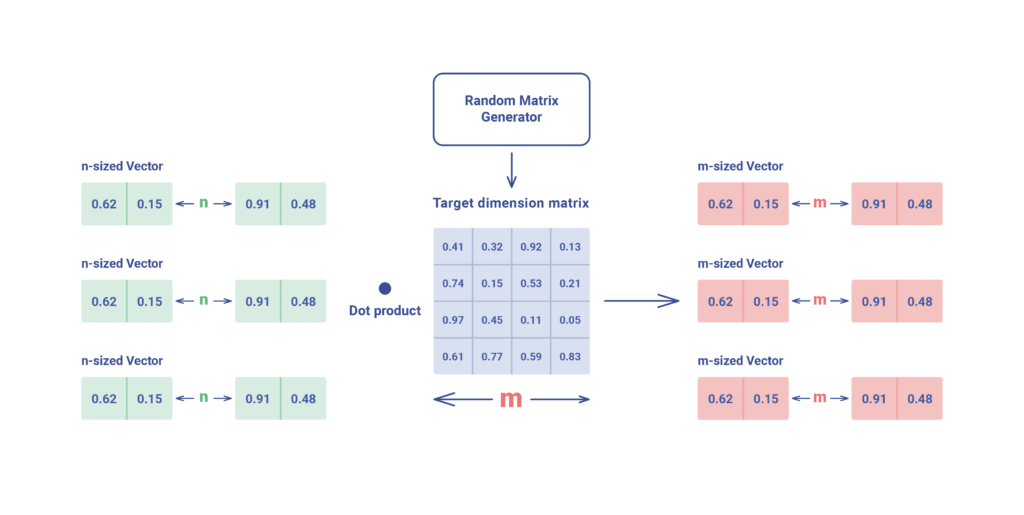
One of the most widely used approaches is to reduce the dimensionality of the vectors while preserving their semantic relationships. A few common techniques include:
Dimensionality Reduction: By multiplying vectors with a random projection matrix, we compress them while retaining key proximity relationships. This speeds up search at the cost of minor precision loss.
Locality-Sensitive Hashing (LSH): Similar to hash maps, LSH places similar vectors into the same “bucket”. When searching, we only examine vectors in the relevant buckets, dramatically reducing computational effort.
In practice, vector search always involves a trade-off between accuracy and latency. Higher precision usually means slower queries, and vice versa.
What Are the Popular Vector Databases?
Here are several well-known and widely adopted solutions used in both open-source and commercial environments:
- Chroma: An open-source vector database tailored for integration with modern AI toolchains. It emphasises ease of use and simplicity for developers working with embeddings and retrieval-augmented generation (RAG). Supported by Humanloop.
- Milvus: A high-performance, cloud-native vector database that supports a wide range of index types. As of version 2.5.6 (released in March 2025), it includes enhanced support for graph-based indices, optimising both speed and accuracy in similarity search.
- Pinecone: A fully managed vector database as a service. It abstracts away infrastructure concerns, allowing teams to scale vector similarity search effortlessly while maintaining strong latency guarantees and production-grade reliability.
- Qdrant: A Rust-based open-source vector search engine developed in Berlin, focused on the specific needs of AI applications. It offers a developer-friendly API and is actively evolving with strong backing from the open-source and startup ecosystems.
- FAISS: Developed by Facebook AI Research, FAISS (Facebook AI Similarity Search) is a popular open-source library used for efficient similarity search and clustering of dense vectors. It is particularly well-suited to research and offline use cases.
- Weaviate: An open-source vector database with modular architecture and semantic search built-in. It supports hybrid search (text and vector) out of the box, and it scales well in distributed environments, offering robust plugin and cloud support.
In addition, PostgreSQL offers a pgvector extension that enables similarity search with embedded vectors, allowing traditional databases to be retrofitted with vector search capabilities.
If you’re looking for a free vector database, several open-source options such as Chroma, Milvus, Qdrant, and Weaviate provide robust capabilities. You can also explore vector database wiki pages for further documentation or test a vector database free on your own infrastructure.
Where Are Vector Databases Used?
Vector databases underpin a wide variety of real-world AI applications:
Search Engines: For semantic search — retrieving results based on meaning, not just keywords. For instance, internal company chatbots with access to documentation (commonly referred to as RAG, or Retrieval-Augmented Generation).
Recommendation Engines: Suggesting films, products, or content that “feel” similar to a user’s preferences.
Computer Vision: Analysing images and video by comparing visual similarity.
Biomedicine: AI-powered databases accelerate drug discovery by finding meaningful patterns in huge biomedical datasets — identifying promising molecules, genes, or treatment targets.
Audio and Voice Processing: Comparing voice samples, finding similar sounds, or tagging audio features.
Multidimensional Data Analysis: Extracting insights from datasets where each data point is described in hundreds or thousands of dimensions.
Conclusion
Vector databases are not “just another database”. They are foundational to a new wave of applications built on semantics, perception, and high-dimensional understanding. Wherever traditional relational systems fall short — especially in scenarios involving similarity, meaning, or complex recommendations — vector databases fill the gap.
They allow developers to move beyond basic data storage, enabling systems that understand and reason about the content they handle. Whether you’re exploring vector databases for AI, building a recommendation engine, integrating vector database files, or implementing semantic search, understanding how vector search technology works gives your application a major edge.
If this overview piqued your interest, we can explore further in future posts — diving into specific algorithms, indexing techniques, benchmark comparisons, and architectural considerations.


