Part 1. This Is Not the Load Balancer You’re Looking For…
When assessing the scope of a new project, we always do our best to estimate the required level of effort as accurately as we possibly can. After all, two of the three sides of the iron triangle of project management depend on it: the time and the budget. However, despite our best intentions, things don’t always go to plan. Deviations from a plan can arise for various reasons. As the work progresses, some new, unaccounted-for factors can reveal themselves. Examples of the most common include:
- additional minor requests and adjustments made by the client
- obscure use cases or flows
- unknown dependencies
- unforeseen technical complications
Some time ago, on an SPG DevOps project, we ran into the latter. To assist the project’s development team, our DevOps engineers were invited onboard. A solution for SaaS auditing and reporting was in the process of transitioning from a one-node “cluster” managed by Docker Swarm to a fully fledged multi-node cluster run under Kubernetes (AWS EKS). Its singular instance had an Nginx Ingress Controller running on it.

The service definition was done in a similar way to the Docker Compose approach, but was slightly enhanced with Swarm, which allowed for updating versions of images without downtime. In this simplified configuration, there was no load balancing as such. The Nginx was receiving all of the traffic, and acting as a proxy. The resulting EKS-based cluster required a load balancer to be configured as well.
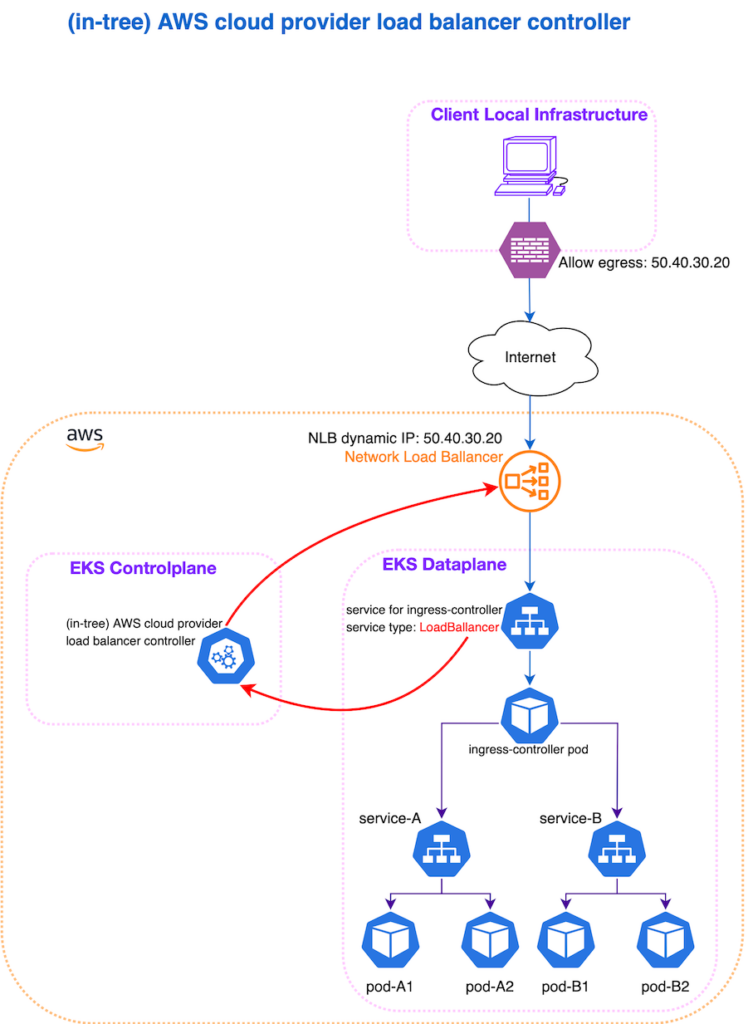
Our original migration plan (and the estimates) included adding load balancing capabilities to an EKS cluster using the AWS Load Balancer. We aimed to utilise an (in-tree) AWS cloud provider load balancer controller that would provide an AWS Network Load Balancer (NLB). This load balancer would then receive all incoming traffic from the internet, and perform proxying functions within the cluster.
DISCLAIMER:
This approach is no longer valid, because the in-tree load balancer controller was deprecated in Kubernetes 1.26. The (in-tree) AWS cloud provider load balancer controller was the legacy, built-in method of provisioning AWS load balancers (ELBs) for Kubernetes Services of LoadBalancer type. Starting from version 2.5, the (out-of-tree) AWS Load Balancer Controller became the default method for provisioning load balancers for services.
What escaped our attention during the preliminary analysis were static IP addresses. This cloud-based solution comes with the agent software, which is installed on-premise, within the end client’s infrastructure. The agent establishes a WebSocket connection with the backend and exchanges data. While this backend is associated with a permanent domain name, some of the end clients, whose infrastructure is enclosed, have to add specific firewall rules to allow any outgoing traffic. For these cases, the backend IP addresses had to be permanent, which meant that our load balancer would have had to be associated with static IP addresses.
Our intended approach assumed that a Kubernetes Service would be associated with the “default” load balancer. However, this load balancer exists only as long as the Kubernetes Service does. If the latter were to be deleted at some point, the same would happen to the load balancer. If, for example, we were to re-deploy our ingress controller, or perform any other action that requires its removal and reinstallation, the load balancer instances would also have been deleted, and the associated IPs would not have been the same. The (in-tree) AWS cloud provider load balancer controller does not allow the utilisation of Elastic IPs (i.e. preserving the IPs), due to its limited functionality. So this task instead had to be resolved using an out-of-tree load balancer setup. This, obviously, required some additional work, resulting in a deviation from our initial estimations.
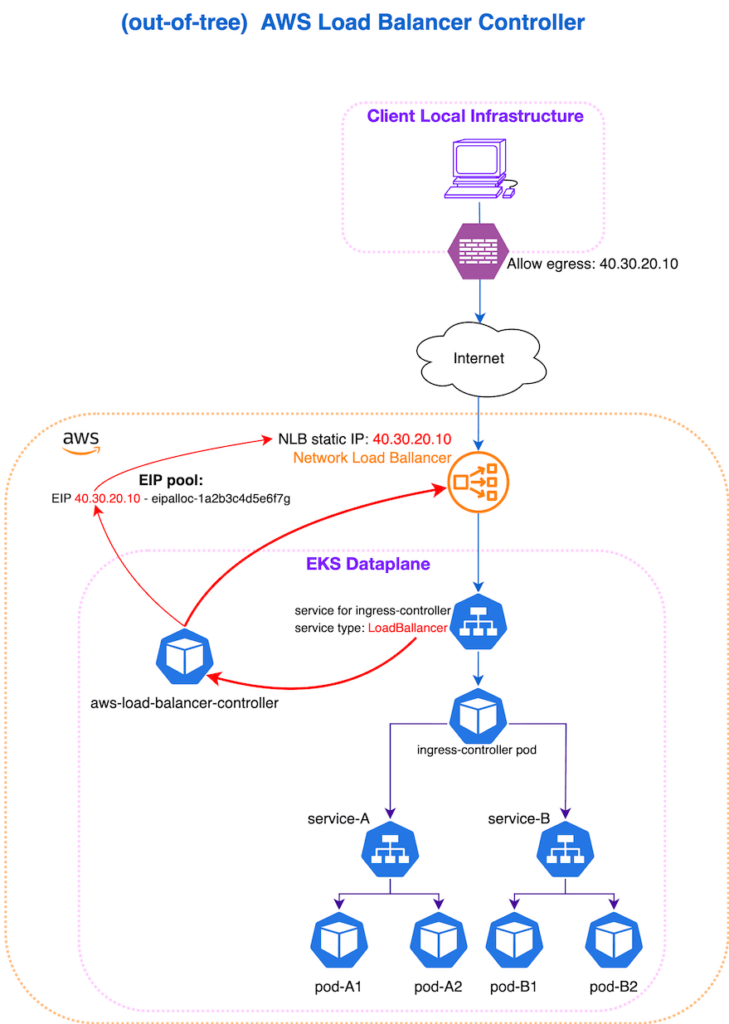
Fortunately, the customer was understanding, and the issue caused no great disturbance.
Part 2. Dressing Up the Message
This was a particularly interesting project. Another “trick” that we used was to help the backend application, working now within a Kubernetes cluster, to “know” the IP addresses of the agents it served (the end users’ IPs).
When the setup included a one-node Swarm cluster, the EC2 instance had its own public IP, which was assigned to a DNS hostname. The Nginx received the original traffic packets, which contained the required requestor’s details. The Nginx would then add this information to the headers of the requests it was sending to the application itself, and extract all of those details from the headers.
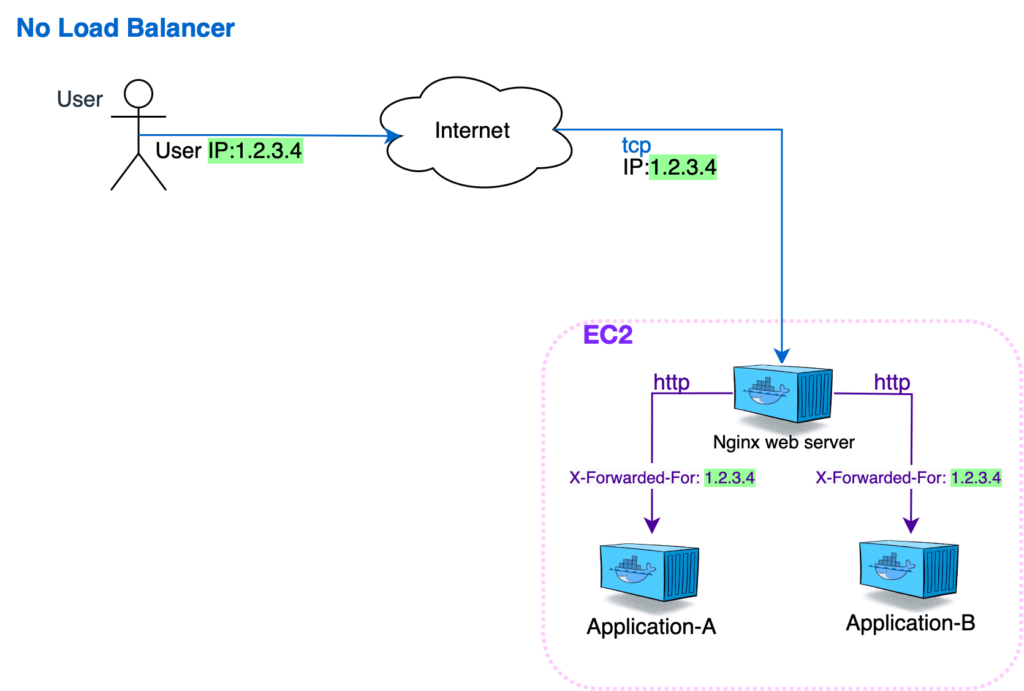
Adding an extra link to our chain, the NLB, changed this. Within this new configuration, all of the packets arriving at the Nginx now contained the IP of our load balancer, and not that of the end user.
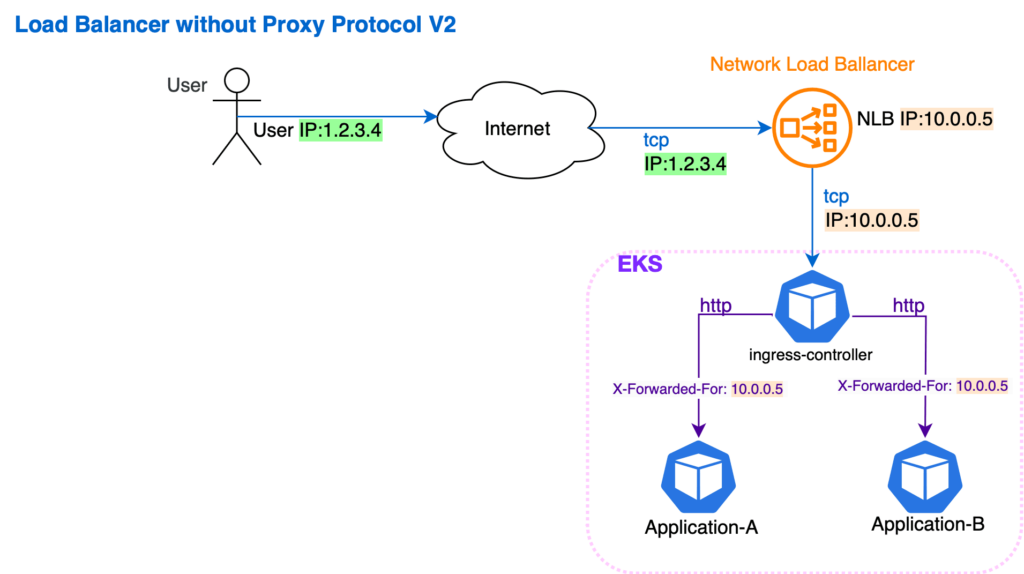
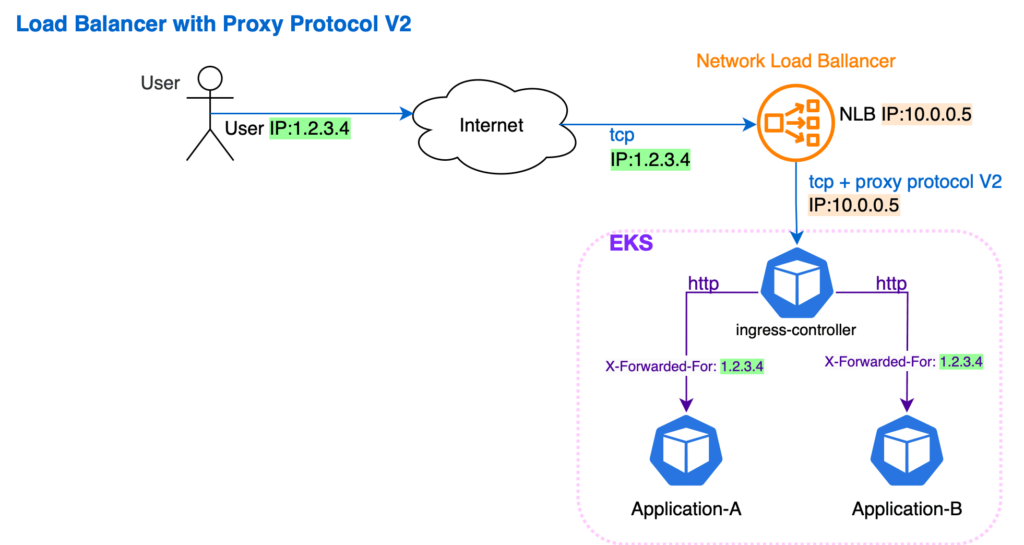
We solved this by using proxy protocol version 2, enabled at both load balancer and Nginx sides. This allowed us to transfer all of the required information via specific TCP headers. The Nginx could now extract the required data, add it to the header, and transfer it further to the back-end application.
The more context and information we have for a certain task, the more accurately we can estimate its complexity and time for implementation. Still, however, the unexpected happens, and some things remain undiscovered until work begins. Contingency planning and careful collaboration are key to getting a project back on track.