
Ah, the joys of cloud computing! Our FinTech project, bustling with activity, had us working extensively with files on AWS S3 and Google Cloud Storage. From PDFs containing insurance information to ancient fixed-length formats from US banks detailing account transactions, we handled it all. Some files came to us via client pushes, others we fetched ourselves via SFTP. Regardless, they all converged in the cloud, embarking on their journey through our file system.
Each step of the file processing involved moving files to specific folders, triggering pipelines based on file type and location. Naturally, our trusty AWS Lambda functions were subscribed to these events. Everything was smooth sailing until we introduced ZIP archives into the mix.

The process should have been seemed straightforward enough:
Unzip the archive
Iterate through the files
Perform actions or simply send them to the correct locations
This workflow was implemented, with everything being extracted to the /tmp directory. Then the magic—or rather, the mayhem—began. Files would sometimes vanish or appear out of thin air. Intrigued? Here’s what happened.

But Where Did They Go?
All instances of your Lambda functions work with the same storage. Imagine Lambda-A writing files to the /tmp directory, only for another instance to start and disrupt the process. The result? Files mysteriously disappearing or multiplying.
Upon encountering this challenge, our team brainstormed several potential solutions:
Ephemeral Storage:
We realised that the /tmp directory is local to each function but shared across invocations within the same execution environment. This ephemeral storage isn’t persistent, and could have led to the issues we faced.
Redis for Caching:
One suggestion was to use ElastiCache (Redis or Memcached) for caching. This would help to manage state between invocations, without relying on the /tmp directory, and prevent file conflicts. But unfortunately, in our case, the file size ruled this option out.
Revised Architecture:
Another approach was to revisit our architecture, potentially utilising Serverless Framework or AWS SAM (Serverless Application Model) and relying on their best practices for managing state and ephemeral storage.
Best Practices
Drawing from our experience and AWS documentation, here are some best practices for managing temporary files in Lambda functions:
Local Variable Scope:
Ensure that data intended for a single invocation is only used within the local variable scope.
File Management:
Delete any /tmp files before exiting and use unique naming conventions (like UUIDs) to prevent different instances from accessing the same files.
Complete Callbacks:
Make sure all callbacks are complete before the function exits to avoid partial processing or file handling issues.
Security Measures:
For high-security applications, consider implementing your own memory encryption and wiping processes before a function exits.
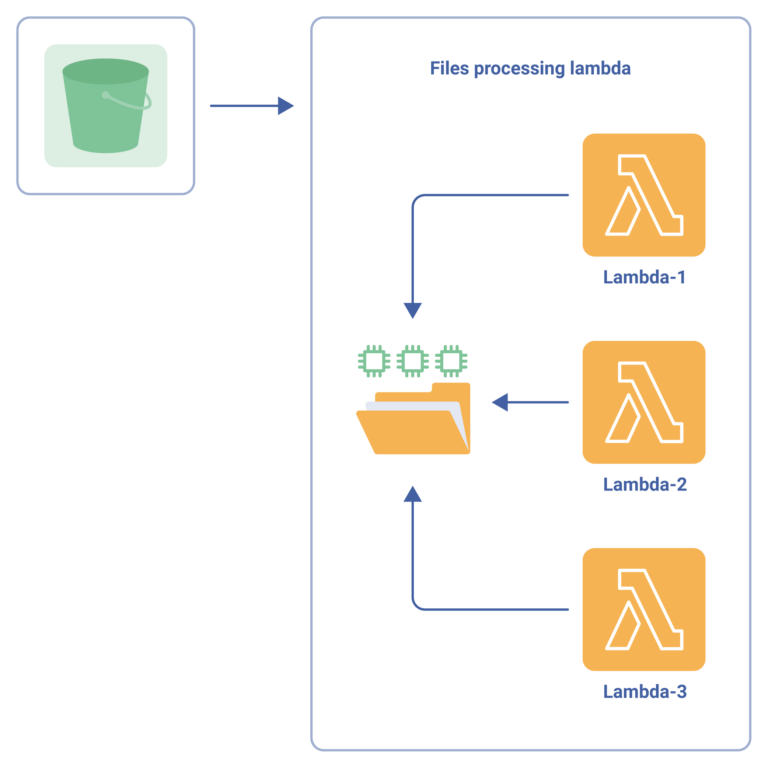
Adhering to these practices helps to avoid the pitfalls of shared ephemeral storage in AWS Lambda functions. In our case, we settled on the approach where each Lambda function generates a unique UUID and stores files in its own folder within the /tmp directory. This prevented conflicts and ensured isolated, reliable file processing.
* * *
This story serves as a reminder of the quirks and challenges of working with cloud services and serverless architectures.


